The future holds a very different internet
In the distant future when we are no longer getting our daily jolt of the day’s news, events, and goings on by reading words on a screen, are we going to still have upvotes and likes? Probably not. Wading through all of that information takes enough time as it is, just imagine how it could be 200 years from now. Finding the best information on a given topic these days often involves lots of reading, scrolling, cross-checking, and googling.
How are we going to figure out the good from the bad?
Google and Wikipedia are a great crutch (right now)
People sometimes tell me, “I would just Google for the answer or look on Wikipedia” when I challenge them to find quality information. For straight-up facts, this does work great and we’re all very happy to have such great resources. But what about less objective things? How would you research what is the best city bike you may want to buy? You’re going to get 15 pages of advertisements, spam blog posts, and near-religious fervor about what what the “best” city bike is.
That’s just one example but I’m sure you could find thousands just by brainstorming: what’s the best way to dice an onion, what are the most comfortable shoes, how do I make my dog sit, etc etc etc.
What lengths we go through today to find what we want
Let’s take a look at the information management controls we currently have. These are the tools that websites provide us to help us identify the information we’re looking for. For example: a highly upvoted post on Reddit, a Pinterest post with a bazillion pins, or a tweet with thousands millions of retweets and favorites.
Go home internet, you’re drunk
The current state of the internet is kind of all over the place, with varying degrees of good and bad ideas implemented in various good and bad ways across the hundreds of websites we all use in our daily lives to get information about things we care about. The roundup of common information controls from across the internet is presented below with some examples and brief commentary on some advantages and disadvantages.
It’s important to note that this is not a comprehensive list of websites, but rather examples of websites which use various types of information management for their users. They all boil down to a few categories, and that is what is presented here. In future posts I will discuss the merits and disadvantages to each of these information management methods.
Also please keep in mind that I’m not trying to critique or rebuke here, just yet. When you keep the thought experiment in mind as you read this post, it’s pretty easy to see how some aspects of todays internet are kind of broken. But that’s okay, we are going to reveal opportunities to improve. The best thing about the internet is that it belongs to all of us, and we collectively get to shape its future! That’s the foundation of this blog. Let’s dig in:
Upvote / Downvote based systems

Reddit, Digg, Facebook, Voat, Pinterest
Upvote and Downvote based systems are common on today’s internet. The core idea is that if more people should see content, it should be upvoted. If people shouldn’t see the content, it gets downvoted. You can see right away how flawed a system this is, but similar to gasoline powered cars it works and gets the job done despite those flaws. The reasons behind an upvote or downvote could be literally anything, and we’ll never know.
For Facebook, they currently don’t even have a down vote option – this has been discussed at length in recent weeks. Facebook augments their up vote data with an a special algorithm in the background to predict content you’ll want to see in the future.
For sites like Reddit, the vote score is just a simple means of deciding what content in their gigantic pile gets presented on all of their various topic pages, and the homepage. Vote scores get translated into karma for the user who submitted the site, and gets used in the future as an indicator of someone who is generally disposed to providing quality content.
Moderated systems
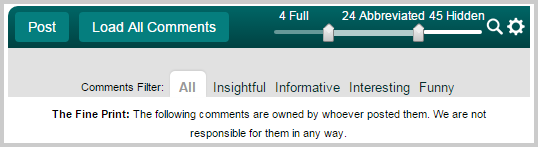
Slashdot’s moderation tags
Moderated systems are more rare on today’s internet, but some have been around for a very long time like Slashdot. Moderation is performed by an ever changing randomly selected pool of registered users. If you’ve been randomly selected, when you visit the site you get the chance to moderate comments on various news stories. By tagging them from a set of pre-defined things such as: funny, interesting, informative, insightful, off topic, and a few more. It provides a rather fine grain of control over what you can see and filter out when you visit the site. It’s not for everyone though – stop for a moment and think about the difference between an internet comment that is informative vs one that is interesting. If you’re seeking out specific types of information from a community for a given topic, this level of detail can be extremely valuable.
Slashdot takes it a step even further, though, and randomly selects a pool of ever changing “meta moderators” who judge the accuracy of the moderation being done. This way if they find a consistently bad actor they can keep them from the pool of moderators in the future and even “undo” their poor moderation of comments.
Sites like Reddit have moderators too, but they function more like de-facto dictators with the ability to completely erase content or block individuals from using the site at all. In that scenario they are not aiding you in finding signal among the noise, they just terminate the signal entirely and erase evidence of it ever existing.
Karma based systems

Reddit, Quora, Stack Exchange
You can think of karma in this context as the trust that a community places in a given person. It is a simple mathematical shorthand to demonstrate that content from a person is from a real person and not a robot or corporation. It is also used to show that the content from the person is usually of good quality, or at least something that a statistically significant number of other people will find interesting.
Given the amount of anonymity prevalent on the internet, it seems almost necessary to provide a karma score, but the idea is still entrenched in an old way of thinking which will be discussed further down in this post.
Peer review systems

Wikipedia, Academic Journals, Newsvine
Peer review is a time tested system which has been around since long before the internet. It’s worth mentioning because the web lends itself to peer review and citation of existing research quite well. Editors of scholarly journals are the curators of high quality content. The end result when peer reviewed research goes online is that it can be trusted. If it had a karma score it would be through the roof.
Plenty of modern websites have a peer review type feature coupled with upvote/downvote: Quora, Stack Exchange, and even Yahoo Answers. It’s pretty simple: people pose a question and the community takes a shot at answering and the “best” answer is determined by up vote score. It would be more accurate to say that the “most popular answer” is determined by up vote count, though, and pretty often it is actually the best answer.
Popularity / Pyramid systems

Facebook, Stumbleupon, Twitter
Many sites use popularity of a given piece of content as criteria for presentation to a wider audience. Popularity based systems are super straightforward – content that is well received will be boosted and shown to more users. Twitter works this way silently and inherently via retweets, Facebook uses algorithms to figure out what to show you, and upvote/downvote sites go by the raw score.
One pretty big flaw with popularity based systems is that there is almost never any indicator of the quality of the content. A blog, news story, or tweet could be wildly popular but completely factually incorrect.
Curated content / Honor system / Familiarity

Upworthy, Newspaper and magazine websites, large blogs, information from people you know in real life
Curated content is managed by one or more editors – newspapers, magazines, research journals, even blogs all have curated content. Our trust in the quality of the content is monolithic: “oh, this is the newspaper in my city.”, or “I’ve written lots of papers citing research in that journal”, or “I know that guy, his blog must be pretty spot on”.
One small problem with curated content currently is of course that yes even newspapers can get their facts wrong from time to time. To find out where the mistakes are you have to come back to that source at some point in the future when they publish a correction or retraction. It happens! Often! The underlying idea is that if you generally trust the source then you also are supposed to generally trust the content. It’s usually not the end of the world when it happens, but if you keep the thought experiment in mind it’s not a model that is going to survive.
So, in summary…
At present lots of websites on the internet today use one (sometimes two!) of the above methods for labeling their content and helping people find the information they want. All sites could have immediate benefit by carefully choosing what combination of information control to implement on their site, almost like a nutrition label for information. For the most part we ignore these flaws day to day and generally muddle through to get to that signal in the noise – but in the future we’re going to need much better indicators for what information we are receiving. Right now it involves lots of scrolling, reading, and cross-checking to uncover the most accurate information for any given topic.
Future blog posts here will discuss (among many other things) better ways to handle all of the above information management controls.
How it could be in the future!
Imagine being able to know right away if that hypothetical tweet with thousands of retweets was factually true or false. Imagine getting the news and knowing right away how trustworthy the source is by actual empirical measurement of their track record. In the future we will have management controls that will instantly shine a spotlight on the best possible information and reveal falsehoods in bad content in excruciating detail. What an amazing asset that would be to humanity! It would represent the internet living up to its ideals – the internet at its best. It will be culture changing. It will change the way people interact. It will swing elections. It will propel science to new heights. It will spawn revolutions.
And we get to create that future internet together. We’ll be talking about THAT also much more on this blog, so please keep coming back!
I hope you found this post interesting! If you did, please sign up for updates or check back. There is much, much more ahead.

Join the Conversation